
Big Data
Die Datenflut der Digitalisierung managen
Die meisten Entwicklungen der Digitalisierung führen zu mehr Daten, mehr Datenabhängigkeit und einer höheren Komplexität.
Mit unseren Angeboten im Bereich Big Data helfen wir Ihnen, mit Daten flexibel umzugehen, sie erfolgreich zu managen und so die Herausforderungen der Digitalen Transformation zu meistern.
Um Kosten und Aufwand zu minimieren, arbeiten wir dabei vor allem mit flexiblen und skalierbaren Lösungen. Das bedeutet: Wir fangen klein an oder nutzen einen ersten Proof of Concept in der Cloud und passen dann die Big Data-Infrastruktur flexibel an.
Wir haben die passende Lösung für Sie
Egal, ob Sie eine Big Data-Lösung für die Integration, Bearbeitung oder Erhaltung von Daten brauchen. Wir arbeiten seit mehreren Jahren mit Oracle zusammen und sind Partner von Cloudera für deren Hadoop Distribution, Amazon Web Services und Talend. Damit können wir auf eine Vielzahl an Technologien zurückgreifen, um für Sie die passende Lösung zu finden – natürlich mit einem genauen Blick auf Ihre Anforderungen und Ihre Infrastruktur.
Cloudera Hadoop Distribution
Das umfangreiche Open Source Ökosystem Hadoop bietet zahlreiche Lösungen, die sich dank einer großen aktiven Community ständig weiterentwickeln. Diese sind gut mit Ihrer Infrastruktur zu kombinieren und zusammen mit einem Cloud-Ansatz besonders flexibel – auch ohne große Investition.
Zugleich ist über Cloudera, die führende Distribution von Hadoop, eine sehr sinnvolle Zusammenstellung der Open Source Lösungen entstanden. Diese wurde mit sehr hilfreichen eigenen Tools von Cloudera aufgewertet und gut abgestimmt gebündelt. Dadurch reduzieren sich der Aufwand und die Risiken im Aufbau einer Hadoop-Lösung deutlich. Projekte können schneller umgesetzt werden und der Koordinationsaufwand sinkt spürbar.
Sie bekommen damit ein umfangreiches Paket von Apache Hadoop mit Apache Spark, Apache Sqoop, Apache Kudu, Apache Flume, Apache HBase, Apache Hive, Apache Impala, Apache Kafka, Apache Parquet, Apache Sentry und einigen mehr. Enterprise ready und mit einem einfachen Subscriptionmodell.
Als Partner von Cloudera haben wir umfangreichen Zugang zu Best Practices, Entwicklungen und Weiterbildungen. Dementsprechend sind viele unserer Mitarbeiter Cloudera-zertifiziert.
Talend
Talend bietet Ihnen gerade für die Daten-Integration im Big Data-Bereich ein umfangreiches Angebot. So gibt es die passenden Connectoren und Jobs für viele der Apache Projekte im Hadoop-Ökosystem und NoSQL-Datenbanken, sowohl in der Cloud als auch On-Premise.
Dadurch lassen sich Themen wie ETL-Jobs, Datenanbindung, Datenmanagement und Datenaufbereitung ganz einfach erledigen.
Als Gold Partner für Consulting und Value Added Reselling (VAR) können wir Sie bezüglich Talend umfangreich beraten und unterstützen – von der Auswahl des optimalen Produkts über die Lizenzierung bis hin zur Umsetzung und dem Support.
Oracle
Neben Hadoop arbeiten wir schon viele Jahre mit klassischen Datenbanken, aber auch speziellen Big Data-Lösungen von Oracle. Diese bieten besonders vielfältige Möglichkeiten – z. B. durch Oracle Data Warehouse, Oracle Data Integrator, die Oracle Datenbanken oder Oracle Big Data Appliance, Oracle Big Data SQL und Oracle Big Data Discovery. Gemeinsam mit Ihnen entwickeln wir ein Konzept, das zu Ihrem Bedarf passt. Wir unterstützen Sie vom Aufbau über die Optimierung bis zur Migration und helfen Ihnen beim Betrieb.
Dabei profitieren Sie nicht nur von unserem Oracle-Know-how, sondern auch von unseren Erfahrungen als Cloudera-Partner: Oracle setzt bei Hadoop auf die Cloudera Hadoop Distribution (CDH). Dementsprechend ist diese Teil der Oracle Big Data Appliance.
Amazon Web Services (AWS)
Als Partner von Amazon Web Services können wir Sie auch über die Vorteile einer Big Data-Lösung in der Cloud beraten: Vom Data Warehouse oder einer Hadoop-Lösung in der Cloud bis hin zur Nutzung von Amazon Lösungen wie AWS Redshift, AWS QuickSight und AWS IoT.
Darüber hinaus unterstützen wir Sie auch bei Amazon Datenbanken wie Amazon DynamoDB oder Amazon S3.
Microsoft
Einige unserer Mitarbeiter haben jahrelange Erfahrung im Microsoft SQL Server-Umfeld. Auf Basis dieses Know-hows beraten wir Sie von der Konzeption über die Implementierung bis zur Optimierung und Migration von Microsoft SQL Server Anwendungen. Sowohl bei einfachen Anwendungen als auch bei komplexeren Data Warehouse oder Big Data Projekten können wir Sie von dem Microsoft SQL Server über die Microsoft SQL Server Integration Services bis hin zur Visualisierung mit Power BI unterstützen.
Open Source Datenbanken
Fast jährlich entstehen neue Datenbanken, viele als Open Source-Lösungen. Beliebter werden vor allem NoSQL-Anwendungen, die speziell für einen Anwendungsfall konzipiert sind. Ihre Zahl ist kaum mehr überschaubar. Um Sie trotzdem tiefgreifend unterstützen zu können, haben wir uns auf die folgenden Open Source-Datenbanken spezialisiert.
- MySQL
- mongoDB
- Apache HBase
- MariaDB
- CouchDB
- PostgreSQL
Sie nutzen in Ihrem Projekt eine andere Datenbank? Unsere Datenbankspezialisten arbeiten sich dank ihres umfangreichen Erfahrungsschatzes schnell in neue Konzepte ein. Sprechen Sie uns also einfach an – wir überprüfen, ob wir Sie hochwertig unterstützen können.
Open Source Software
Gerade im Umfeld von Big Data gibt es neben den vielen Open Source-Datenbanken auch unzählige Open Source-Tools und Software-Lösungen. Wir unterstützen Sie vor allem bei der folgenden Open Source-Software:
- Apache Kafka
- Apache Spark und Spark Streaming
- Apache Impala
- Apache Kudu
- Apache Flume
Tableau
Ähnliche wie Qlik bietet auch Tableau zahlreiche Möglichkeiten, Daten und Analyseergebnisse mit Hilfe von Reports, Dashboards und Grafiken zu visualisieren. Und wie Qlik geht auch Tableau über die reine Visualisierung hinaus. Sie können Daten auch aufbereiten, ihre Qualität sichern und sie analysieren.
Tableau arbeitet sehr gut mit der Cloudera Hadoop Distribution und entsprechenden Tools wie Apache Impala, Apache Kudu und Apache Spark zusammen. Für uns ist Tableau bei Kunden mit einer Hadoop Infrastruktur dementsprechend eine beliebte Plattform für Datenanalyse und Datenvisualisierung.
Unsere Leistungen
Wir unterstützen Sie in allen Aspekten des Bereichs Big Data. Von der Optimierung und Einbindung der Datenquellen bis zur Datenintegration. Von der Datenbearbeitung bis zu Datenhaltung, Datenanalyse und Visualisierung.
Analyse
Wir analysieren für Sie Ihre Dateninfrastruktur, von klassischen Datenbanken über NoSQL Datenbanken bis hin zu umfangreichen Hadoop Installationen. Hierbei betrachten wir die Performance Ihrer aktuellen Systeme, Ihr Datenmanagement und die Komplexität Ihrer Datenstruktur. Das Ergebnis: ein umfangreicher Bericht mit Empfehlungen unserer Experten.
Big Data-Workshops
In unseren Big Data-Workshops stellen wir Ihnen die Vor- und Nachteile verschiedener Big Data-Lösungen vor und analysieren mit Ihnen die Vor- und Nachteile für Ihr Unternehmen. Unsere Empfehlungen zur optimalen Lösung mit der passenden Architektur fassen wir für Sie konkret in einem Abschlussbericht zusammen. Die Hintergründe und Details dazu besprechen wir mit Ihnen.
Datenbank-Services – Beratung und Optimierung
Auch Ihre existierenden Datenbanken spielen im Datenmanagement eine wichtige Rolle: Neben den spezialisierten Big Data-Technologien tragen sie einen wesentlichen Teil zu einer erfolgreichen Datenstrategie bei.
Dienstleistungen rund um Datenbanken gehören schon seit über 10 Jahren zu unserem Portfolio –von der Konzeption bis zum Betrieb. Dementsprechend unterstützen wir Sie in allen Fragen zu Ihren Datenbanken, egal ob Oracle, Microsoft SQL Server, MongoDB, MySQL, PostgreSQL oder Amazon DynamoDB, Apache HBase und weiteren.
Insbesondere für Oracle und Microsoft SQL-Server haben wir in den letzten Jahren herausragendes Expertenwissen aufgebaut. Unsere Mitarbeiter halten regelmäßig Fachvorträge auf diversen Veranstaltungen – z. B. auf Events der Deutschen Oracle User Group (DOAG).
Beratung – Use Case, Technologie, Umsetzung
Gerne beraten wir Sie schon in der Prüfung Ihrer Anforderungen, der Gestaltung Ihres Use Cases und der Auswahl der entsprechenden Big Data-Technologien. Das passende Umsetzungskonzept oder Vorgehensmodell erarbeiten wir gemeinsam mit Ihnen.
Aufbau Ihrer Datenstrategie und Ihres Datenmanagements
Ein durchdachtes Datenmanagement und eine unternehmensweite Datenstrategie schaffen Transparenz über die Daten, die Möglichkeiten und den Umgang mit ihnen – im gesamten Unternehmen. Gemeinsam mit Ihnen erarbeiten wir Ihre Datenstrategie und die Richtlinien für Ihr Datenmanagement.
Planung und Konzeption
Gerne übernehmen wir die Planung von Big Data-Lösungen und schlagen Ihnen unterschiedliche Konzepte für die Bedürfnisse Ihres Unternehmens vor. Gemeinsam bewerten wir die verschiedenen Möglichkeiten, erarbeiten ein umsetzbares Konzept und geben Ihnen eine konkrete Empfehlung.
Proof of Concept
In unseren Augen muss man nicht immer gleich mit einem großen Big Data-Projekt beginnen. Im Gegenteil. Ganz nach dem Motto „Think Big, start small, learn and grow fast.” starten wir oft erst mit einem kleinen Proof of Concept. So können wir mit geringem Aufwand die Möglichkeiten austesten und die Vorteile für Ihr Unternehmen prüfen.
Das hält Ihre Investitionen so gering wie möglich: Dank Open Source-Lösungen zahlen Sie keine hohen Lizenzgebühren. Wenn Sie den Proof of Concept in der Cloud durchführen, sparen Sie sich außerdem Kosten für umfangreiche Hardware. Finden und testen Sie die die passende Lösung mit geringem Aufwand.
Aufbau Ihrer Big Data Lösung
Wenn das Konzept und die Architektur Ihrer Big Data-Lösung feststehen, unterstützen wir Sie natürlich auch bei der Umsetzung und ihrem Aufbau. Dabei profitieren Sie vor allem von unseren Erfahrungen im Ökosystem von Hadoop, insbesondere in der Cloudera Hadoop Distribution, aber auch von unserem Know-how rund um Big Data- und Data Warehouse-Lösungen von Oracle, Amazon und Microsoft.
Datenintegration, Entwickeln entsprechender Jobs und Prozesse
Wir beherrschen nicht nur diverse Open Source Tools für die Datenintegration, die Anbindung Ihrer Datenquellen und die Entwicklung entsprechender Integrations- und Datentransformations-Jobs. Als Talend Gold Partner sind wir auch Experten für die verschiedenen Talend Produkte. Mit unserem Know-how und unseren Erfahrungen können wir Sie bei Ihren ETL- und ELT-Jobs umfangreich unterstützen – von der Definition über die Umsetzung bis zur Optimierung und Pflege.
Optimierung der Datenbasis, der ETL- und Integrations-Jobs, der Big Data Lösung und der Abfragen
Wir sichern den performanten Einsatz Ihrer Lösungen und vermeiden, dass aus Ihrem Data Lake ein Datentümpel wird: Dazu analysieren und optimieren wir Ihre Datenbasis genauso wie die Datenintegration, Ihre Big Data-Lösung und die entsprechenden Abfragen regelmäßig.
Support und Weiterentwicklung
Wir helfen Ihnen, Ihre Lösung dauerhaft leistungsfähig zu halten und sie nach Ihren Anforderungen weiterzuentwickeln. Dazu unterstützen wir Sie bei der kontinuierlichen Pflege und Weiterentwicklung Ihrer Data Warehouse- oder Big Data-Lösungen.
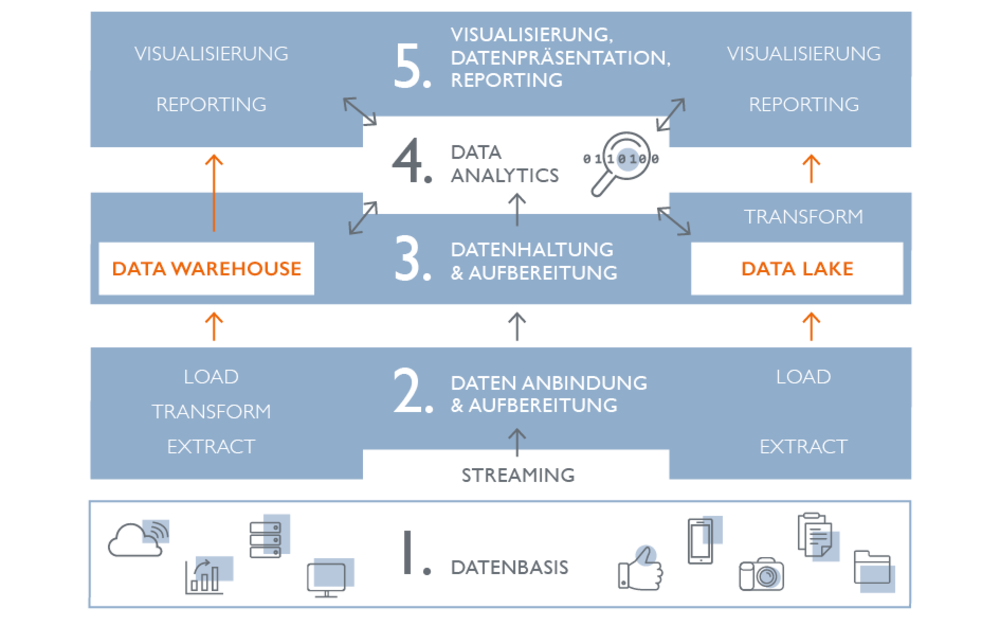
Unsere Sicht auf die Welt von Big Data und Business Intelligence
Big Data ist ein sehr umfangreicher Bereich. Er reicht in unserem Verständnis von der Datenbasis und den unterschiedlichen Datenquellen bis zur Anbindung und Aufbereitung, von der Datenhaltung und der Analyse bis zum Visualisieren in Form von Reports, Dashboards und Grafiken. Wir haben in allen Bereichen Erfahrungen und können Ihnen dank unserer Partnerschaften zahlreiche Lösungen anbieten.
Datenbasis
Ein wichtiger Grund für Big Data-Lösungen ist die steigende Komplexität der Datenbasis. Neben den klassischen strukturierten Daten müssen immer mehr unstrukturierte Daten verarbeitet werden – teilweise in Quasi-Echtzeit. Wichtige Treiber hierfür sind unter anderen das Internet of Things (IoT), die steigende Automatisierung und Social Media.
Dementsprechend hat sich auch die Landschaft der Datenquellen deutlich verändert, die in eine Big Data-Lösung integriert werden müssen. Neben den traditionellen Datenbanken kommen vermehrt spezialisierte NoSQL-Datenbanken zum Einsatz.
Wir haben jahrelange Erfahrung in der Datenbank-Beratung, Datenbank-Optimierung und Datenbank-Pflege. Dadurch können wir Sie im Bereich von Datenbasis und Datenquellen umfangreich unterstützen.
Bei den traditionellen Datenbanken liegt unser Schwerpunkt auf Oracle, Microsoft SQL Server, MySQL und PostgreSQL. Zugleich sind wir Experten in neueren Lösungen wie MongoDB, CouchDB, HBase, Amazon S3 oder Amazon DynamoDB – in der Cloud oder On-Premise.
Datenanbindung, -integration und -aufbereitung
Die richtige Anbindung und Integration der Daten ist ebenso wichtig wie ihre korrekte Aufbereitung. Daher unterstützen wir Sie in allen drei Bereichen.
Bei der Datenanbindung kann es unter anderem um Schnittstellen zwischen mehreren Anwendungen, um MessageBroker oder um die Datenübernahme aus diversen Datenbanken in einen zentralen Enterprise Data Hub gehen. Dementsprechend gibt es viele Möglichkeiten. Wir helfen Ihnen die passende zu finden.
Ziel der Datenaufbereitung ist es, Formate zu vereinheitlichen – insbesondere bei sehr unterschiedlichen Datenquellen. In vielen Fällen erfordern z. B. die Datenschutzbestimmungen auch bestimmte Meta-Daten wie Informationen zum Erfassungsdatum, dem Erfasser und der Speicherfrist.
Zur Integration und Aufbereitung von Daten werden in der Regel Integrations- und Transformationsjobs geschrieben – sogenannte ETL (Extract, Transform, Load) oder ELT (Extract, Load Transform). Hierfür gibt es für die verschiedenen Plattformen unterschiedliche Tools, aber auch plattformunabhängige Lösungen.
Wir beherrschen die gängigen Tools in der Hadoop Umwelt, für Oracle, Microsoft und Amazon Web Services. Durch unsere Partnerschaft mit Talend können wir außerdem ein umfassendes plattformunabhängiges Integrationstool nutzen.
Datenhaltung und -bearbeitung
Ob in klassischen Datenbanken, traditionellen Data Warehouse-Lösungen oder modernen Big Data-Anwendungen: Die optimale Datenhaltung ist performant, zuverlässig, flexibel und sicher.
In vielen Fällen reicht eine klassische Datenbank dazu aus. Die Anforderungen steigen aber mit der Größe der Dantenmenge und der Komplexität der Datenstruktur.
Wir helfen Ihnen, die passende Datenstrategie und Architektur zu entwickeln und den richtigen Ansatz zu finden, um diese Herausforderungen zu meistern. Dank unserer langjährigen Erfahrung in Datenbanken und unserer Partnerschaft mit Cloudera und Amazon Web Services (AWS) können wir dazu auf besonders viele Möglichkeiten zurückgreifen, um den passenden Ansatz für Sie zu finden.
Ansätze, mit denen wir arbeiten:
- Cloudera Hadoop Infrastruktur, in der Cloud oder On-Premise
- AWS Big Data-Lösungen
- Oracle Big Data Appliance
- Spark Streaming
- Microsoft SQL Server
- Data Warehouse von Oracle oder Microsoft
Data Analytics
Daten sind ein wichtiger Erfolgsfaktor – wenn man sie analysiert. Nur so kann man aus ihnen tiefe Erkenntnisse und nützliche Informationen gewinnen. Data Analytics-Anwendungen ergänzen Big Data-Lösungen daher sinnvoll. Aus diesem Grund bieten viele Data Analytics-Plattformen auch Lösungen für die Visualisierung von Daten und Analyseergebnissen in Form von Reports, Grafiken und Dashboards. Wir unterstützen Sie mit unserem umfangreichen Know-how im Bereich Data Analytics. Mehr erfahren
Datenpräsentation, Visualisierung und Reporting
Die Art und Weise, wie Sie Daten und Ergebnisse einer Analyse präsentieren, entscheidet darüber, wie schnell und unkompliziert Mitarbeiter in Ihrem Unternehmen diese bewerten und nutzen können.
Standard-Produkte wie QlikView, Microsoft Power BI oder Tableau sind einfach zu implementieren und leicht zu nutzen. Mit ihnen können Sie häufig sehr gute Übersichten, Tabellen, Grafiken, Statistiken und Analysen erstellen. Je nach Bedarf kann es aber auch sinnvoll sein, die Visualisierung und Berichte in Ihre Anwendung zu integrieren oder sogar eine neue Anwendung zu programmieren.
Egal, welche Option die passende für Sie ist: Wir unterstützen Sie mit unserem umfangreichen Know-how. Ob mit Open Source-Lösungen wie JasperReport, über Java Frameworks wie Primefaces oder Oracle APEX – wir entwickeln die optimalen Berichte oder das passende Dashboard für Ihre Daten. Natürlich auch responsive oder als native App. Damit Sie Ihre Anwendung auch auf mobilen Endgeräten nutzen können.
Die klassischen Kriterien für Big Data
Volume – die Datenmenge.
Variety – die Datenkomplexität aus unterschiedlichen Typen wie strukturierten und unstrukturierten Daten.
Velocity – die Geschwindigkeit der Datenverarbeitung.
Veracity – die Vollständigkeit bzw. Richtigkeit der Daten.
Warum für uns Data Warehouses in der Welt von Big Data verankert sind
Vielleicht wundern Sie sich über den Punkt Data Warehouse-Lösungen in unserer Übersicht. Schließlich arbeiten traditionelle Data Warehouse-Lösungen meistens vorwiegend mit strukturierten Daten. Auch wenn damit das Kriterium Variety der klassischen Definition von Big Data-Lösungen nicht erfüllt ist: In unseren Augen sind Data Warehouses trotzdem eng mit der Big Data-Welt verbunden. Denn gerade moderne Big Data-Lösungen wie Data Lakes sind oft eng mit Data Warehouse-Anwendungen verknüpft. Sie ergänzen und überscheiden sich.
Data Warehouses und Data Lakes
Klassische Data Warehouses galten lange als strukturiert und kontrolliert, aber zugleich unflexibel und wenig performant. Daher wurden Data Lakes entwickelt, um eine flexible und kostengünstige Infrastruktur zu schaffen. Der Nachteil: Lädt man unkontrolliert viele Daten in eine Big Data-Lösung, kann auch viel Datenmüll entstehen. Heute verwendet man häufig beide Modelle in Kombination – ein Beispiel dafür, wie eng Data Warehouses mit dem Bereich Big Data verzahnt sind.
Die Anfänge: das klassische Data Warehouse-Modell
Das klassische Data Warehouse war über Jahrzehnte das zentrale System im Bereich Business Intelligence (BI). Hierbei wurden strukturierte Daten, fast ausschließlich aus relationalen Datenbanken, mittels ETL-Jobs extrahiert, bearbeitet und in das Data Warehouse geladen. Dort konnte ein begrenzter Nutzerkreis dann auf die meist kaufmännischen Daten zugreifen und diese mittels Berichten auswerten – ein sehr strukturierter und kontrollierter aber dafür unflexibler und wenig performanter Prozess. Oft war die benötigte Infrastruktur für klassische Data Warehouse-Lösungen auch sehr teuer und mit aufwendiger Wartung verbunden.
Da sich Data Warehouse-Ansätze nicht mit unstrukturierten Daten und Quasi-Echtzeit-Anforderungen beschäftigen, gehören Sie strenggenommen auch nicht zur Big Data-Welt.
Konzipiert als Gegenmodell: Data Lakes
Für einige Zeit wurde dann der Data Lake quasi als Gegenmodell zum klassischen Data Warehouse dargestellt. Die immer stärkere Verbreitung von Hadoop als flexible Open Source-Lösung, bei der komplexe Massendaten auf kostengünstiger Standard-Hardware gespeichert werden können, hat sicherlich sehr stark zu diesem Trend beigetragen.
Entwickelt wurden Data Lakes mit dem Ziel, eine flexible und kostengünstige Infrastruktur zu schaffen, die zum einen durch Hinzufügen von Standard-Hardware flexibler skalierbar ist, zum anderen aber auch mit unstrukturierten Daten besser umgehen kann.
Auf dieser Basis war es nicht mehr notwendig, Daten genau auszuwählen. Schnell wurden deshalb erst einmal alle möglichen Daten in „Daten-Seen“ hochgeladen und gespeichert. Man konnte die Daten ja bei der Abfrage und Weiterverarbeitung bearbeiten und auf ihre Qualität prüfen. So ist der Extract Load Transform (ELT) Prozess entstanden.
Heute werden beide Modelle verknüpft
Natürlich führte ein unkontrolliertes Hochladen von Daten in eine Big Data-Lösung wie einen Data Lake häufig auch zu viel Datenmüll. Und auch mit Hadoop verursachte das Speichern von sinnlosen Datenmassen unnötige Kosten. Gleichzeitig hatten sich auch die Data Warehouse Technologien deutlich weiterentwickelt. Aus diesem Grund sind die beiden Konzepte heute keine Gegensätze mehr.
Viel mehr versucht man, durch ihre gezielte Kombination die jeweiligen Vorteile zu nutzen.
Wie ergänzen sich beide Modelle – ein Anwendungsfall
Es gibt einige Anwendungsfälle, die den Mehrwehrt einer abgestimmten Lösung mit einem Data Warehouse und einer Big Data-Lösung verdeutlichen. Ein häufiges Beispiel ist die Archivierung von Daten aus dem Data Warehouse in Big Data-Lösungen: Ältere Daten im Data Warehouse werden in der Regel archiviert – das ist oft nur außerhalb des Data Warehouse möglich. Damit stehen die archivierten Daten nicht mehr für Auswertungen, Reports und Abfragen zur Verfügung. Verschiebt man diese Altdaten allerdings beispielsweise in eine Hadoop Lösung, wird das Data Warehouse auch entlastet. Das verbessert die Performance und reduziert Kosten, da Speicherplatz in Hadoop in der Regel um ein Vielfaches günstiger ist als in einer Data Warehouse-Lösung. Zusätzlich können moderne Business Intelligence- und Data Analytics-Lösungen sowohl auf das Data Warehouse als auch auf die Hadoop Lösung zugreifen. Dadurch sind auch weiterhin umfangreiche Abfragen, Auswertungen und Reports inklusive der Altdaten möglich.
Die passende Lösung zur Datenintegration – ETL vs. ELT
Sollte man Daten aufbereiten, bevor sie im Zielsystem landen, oder erst später bei ihrer Weiterverarbeitung? Sowohl ETL als auch ELT beschreiben eine Reihenfolge von Prozessen im Umgang mit Daten. Beide Varianten haben Vor- und Nachteile. Wir helfen Ihnen, die passende zu finden.
ETL
Die klassische Reihenfolge, die in den meisten Anwendungen genutzt wird: Daten werden aus einem Quellsystem extrahiert (E – Extract), aufbereitet und bearbeitet (T – Transform) und dann in das Zielsystem geladen (L – Load).
ELT
Eine Reihenfolge, die häufig in einem sehr dynamischen Umfeld und im Zusammenhang mit Big Data-Lösungen sinnvoll ist: Daten werden aus dem Quellsystem übernommen (E – Extract), ohne Bearbeitung direkt in die Big Data Lösung geladen (L – Load) und erst bei der Weiterverarbeitung aufbereitet (T – Transform).
Unsere Angebote im Bereich Datenintegration
Neben den Daten-Integrations-Tools diverser Hersteller wie Oracle und Microsoft arbeiten wir auch mit Open Source-Lösungen und herstellerunabhängigen Tools, insbesondere Talend.
Talend ist die führende Plattform zur Daten-Integration und -Aufbereitung – unabhängig davon, ob Sie die Daten in ein Data Warehouse von IBM oder Oracle, in einem Hadoop-Cluster oder in unterschiedlichen Datenbanken halten. Dank über 900 Connectoren profitieren Sie von einer schnellen und einfachen Daten-Integration mit der nötigen Datenbearbeitung und der entsprechenden Qualitätssicherung.
Als Talend Gold Partner (Value-Added Reseller) können wir Sie bezüglich der Talend Produkte und Lösungen nicht nur beraten und unterstützen, sondern auch die entsprechenden Produkte und Services anbieten – entlang des gesamten Lebenszyklus. Von der ersten Beratung über die Projektumsetzung bis hin zum Support.
Unsere Antworten auf Fragen im Bereich Big Data
Warum Big Data-Lösungen für IoT-Projekte sinnvoll sind
Internet of Things (IoT) steht für die Vernetzung von Geräten und Sensoren. Genau diese Vernetzung steigert das Datenaufkommen erheblich. Dabei entstehen insbesondere auch Unmengen an unstrukturierten Daten. Logfiles, Kommunikationsprotokolle, Sensordaten oder Geo-Informationen sollen meist in Quasi-Echtzeit empfangen, verarbeitet und ausgewertet werden. Das ist mit traditionellen Datenbanksystemen kaum möglich. Deshalb sollten Sie sich in jedem IoT-Projekt auch um Big Data-Lösungen Gedanken machen. Wir beraten Sie gerne zu Ihren Möglichkeiten.
Big Data für den Mittelstand
Big Data Lösungen steigern die Effizienz, helfen Kunden zu binden und damit den Umsatz und den Erfolg nachhaltig zu steigern – vor allem bei mittelständischen Unternehmen. Zugleich sind sie schon lange kein Privileg von Großkonzernen mehr: Durch die vielfältigen Open Source-Angebote kombiniert mit den Möglichkeiten der Cloud, können Big Data Projekte auch ohne riesige Budgets erfolgreich umgesetzt werden. Wir helfen Ihnen, die passende Lösung zu finden und diesen Erfolgsfaktor zu nutzen.
Warum Datenschutz, Security und das richtige Datenmanagement vor allem für Big Data-Lösungen wichtig sind
Speicherdauer, Anonymisierung, geregelte Datenschutzmaßnahmen und Zugriffsrechte: Eine durchdachte Datenstrategie ist vor allem bei Big Data-Lösungen wichtig. Denn so viele Chancen die wachsende Datenmenge auch eröffnet; sie erfordert zugleich mehr Verantwortung: Die Anforderungen des Datenschutzes steigen genauso wie die Strafen. Skandale durch gestohlene Daten schaden dem Image.
Als Cloudera Partner können wir Ihnen hier, insbesondere im Hadoop-Umfeld, umfangreiche Möglichkeiten anbieten. Gerne erarbeiten wir mit Ihnen eine umfassende Datenstrategie, beraten Sie bezüglich Sicherheitsaspekten Ihrer Datenbanken und Big Data-Lösungen. Natürlich zeigen wir Ihnen auch die Möglichkeiten einer datenschutzkonformen Anwendung.
Data Agility
Ein agiler und flexibler Umgang mit Daten wird für den Erfolg Ihres Unternehmens immer wichtiger – stellt die IT aber vor steigende Herausforderungen: Daten werden immer komplexer, eine Auswertung in Quasi-Echtzeit ist häufig erforderlich – genauso wie eine Demokratisierung über Abteilungsgrenzen. Schließlich lassen sich Entscheidungen besser treffen, wenn alle Einblick in Informationen haben. Natürlich sollte der Zugriff auf Daten zugleich so einfach sein, dass auch Nicht-IT-Experten Abfragen erstellen und auswerten können (Self-Service-BI).
Vor diesen Herausforderungen stoßen klassischen Datenbankstrukturen oft an ihre Grenzen. Flexible und skalierbare Big Data-Lösungen sind dann genauso gefragt, wie eine geschickte Daten-Integration und -bearbeitung oder ein strategisches Datenmanagement.